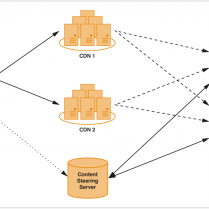
Generative AI & Content Recommendation
Many major broadcasters are at least investigating how Generative AI can enhance content recommendation, partly by exploiting the ability to combine attributes across video, audio, text and graphics. These are early days though, with research still being conducted by universities and other academic institutions, as well as broadcasters themselves.